RAG (Retrieval-Augmented Generation hay “Tạo sinh tăng cường bằng truy xuất thông tin”) không chỉ đơn giản là Truy xuất vector từ văn bản → đưa vào prompt → LLM trả lời, mà có nhiều cách thực thi (biến thể) khác nhau giúp cho việc truy xuất thông tin hiệu quả và chính xác hơn. HyDE (Hypothetical Document Embeddings) RAG là một trong những kỹ thuật như vậy.
✅ HyDE là gì?
HyDE (viết tắt của Hypothetical Document Embeddings) là một kỹ thuật do OpenAI đề xuất năm 2022 trong bài:
📄 “Improving Retrieval with Hypothetical Document Embeddings” 🔗 Arxiv paper
Thay vì lấy embedding từ truy vấn gốc (user query) để tìm tài liệu phù hợp, HyDE làm một việc thông minh hơn:
🧠 Gợi ý một “văn bản giả định” (hypothetical answer) cho truy vấn → Sau đó lấy embedding của văn bản này để truy xuất tài liệu.
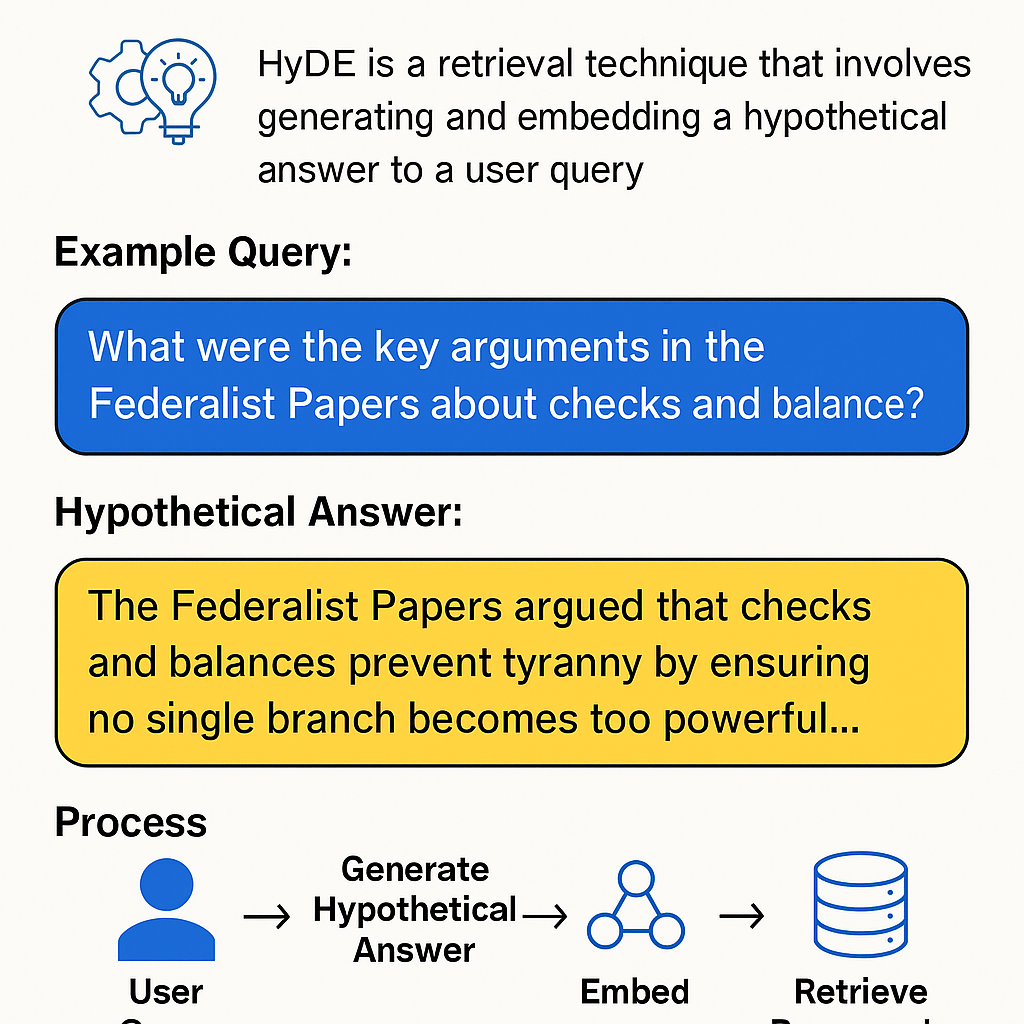
📌 Ví dụ trực quan
Câu hỏi người dùng:
“What were the key arguments in the Federalist Papers about checks and balances?”
🔸 RAG thường:
- Lấy embedding của câu hỏi → tìm tài liệu gần nhất → đôi khi không khớp tốt vì văn phong truy vấn và tài liệu khác nhau.
🔸 HyDE:
- GPT tạo trước một văn bản mô phỏng nội dung phù hợp như:
- Lấy embedding của đoạn văn trên để tìm tài liệu liên quan trong vector DB.
🎯 Kết quả: Tìm được các đoạn thực sự chứa nội dung liên quan đến “checks and balances” trong Federalist Papers.
⚙️ Quy trình HyDE chi tiết:
User query →
GPT tạo "hypothetical answer" →
Embedding hypothetical answer →
Truy xuất tài liệu từ vector DB →
GPT trả lời dựa trên kết quả💡 Vì sao HyDE hiệu quả hơn?

🧱 Khi nào nên dùng HyDE?
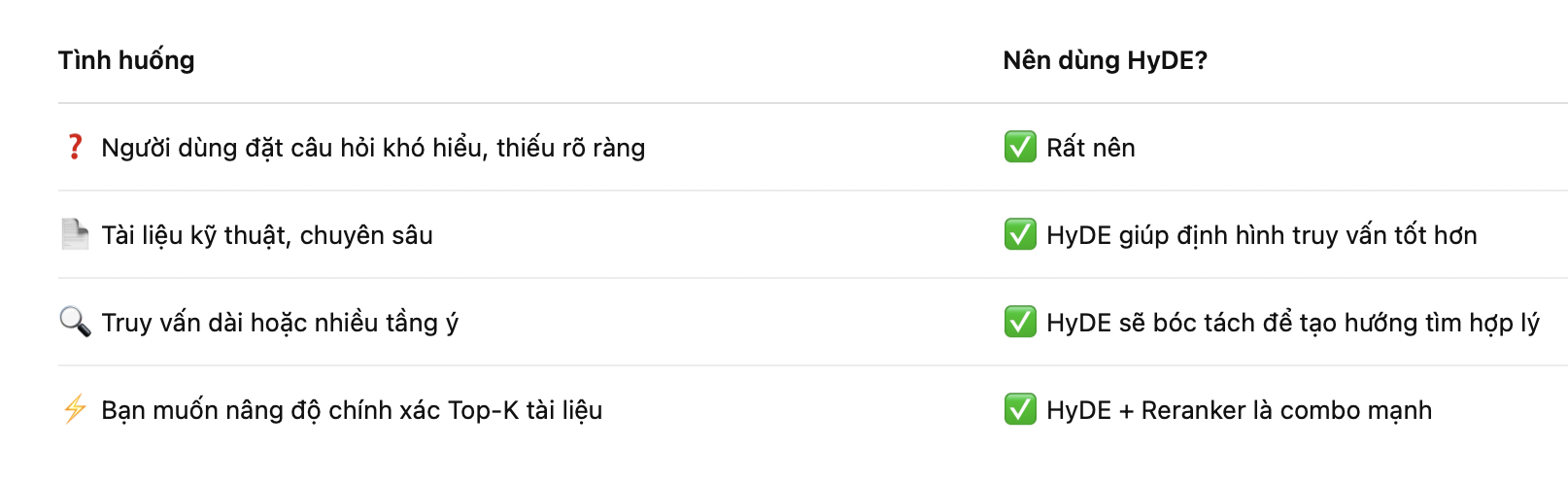
🧪 So sánh RAG thường vs HyDE

🛠️ Cách triển khai HyDE đơn giản (pseudo-code)
# Step 1: Generate hypothetical document from user query
hypo_answer = llm.generate("Write a short paragraph answering: " + user_query)
# Step 2: Embed hypothetical answer
embedding = embed_model.embed(hypo_answer)
# Step 3: Search documents using embedding
docs = vector_store.similarity_search(embedding)
# Step 4: Feed docs + query back to LLM to generate final answer
response = llm.generate(context=docs, question=user_query)🛠️ Công cụ hỗ trợ HyDE hiện nay

📌 Lưu ý khi dùng HyDE
- Không phải lúc nào cũng tốt hơn: nếu query đã rất rõ, HyDE có thể làm chậm pipeline.
- Gợi ý prompt tạo văn bản cần rõ ràng: “Write a short paragraph that answers…” là cách dễ hiệu quả.
- Nên cache kết quả của bước hypothetical document nếu có thể để giảm chi phí/gọi lại.
🔚 Tóm lại:
HyDE là một chiến lược “gợi ý trước rồi tìm sau”, giúp AI truy xuất tài liệu tốt hơn bằng cách giả định thông tin cần tìm, đặc biệt hiệu quả trong các tình huống phức tạp, truy vấn mơ hồ, hoặc người dùng không biết mình đang hỏi gì rõ ràng.