🚀 Boosting Retrieval Quality with HyDE RAG
RAG (Retrieval-Augmented Generation) isn’t just about fetching vectors from text → inserting them into a prompt → and letting an LLM answer.
There are several variants and techniques that make information retrieval more efficient and accurate — one of the most notable being HyDE (Hypothetical Document Embeddings) RAG.
✅ What is HyDE?
HyDE (short for Hypothetical Document Embeddings) is a technique proposed by OpenAI in 2022 in the paper:
📄 “Improving Retrieval with Hypothetical Document Embeddings” 🔗 Arxiv paper
Instead of taking the embedding of the original query to find matching documents, HyDE does something smarter:
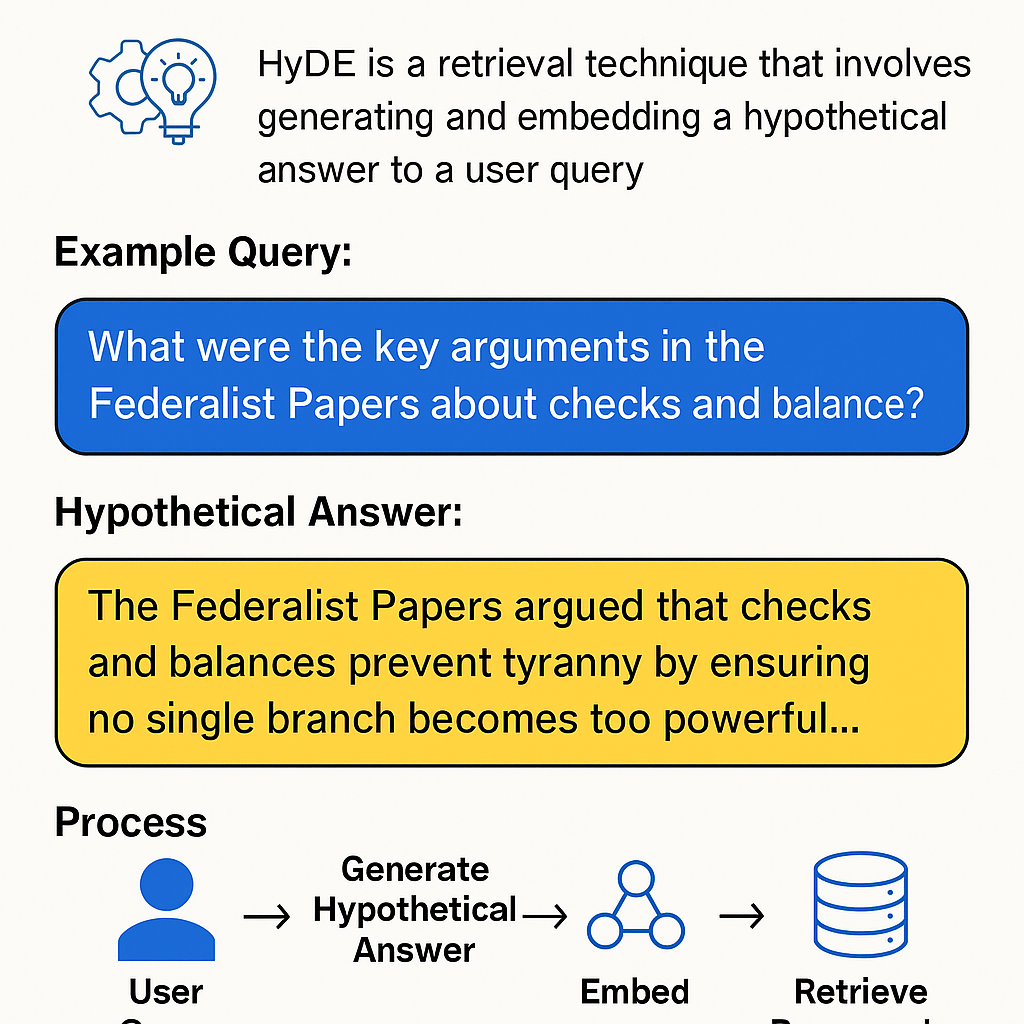
🧠 It first generates a “hypothetical answer” — a short piece of text that might plausibly answer the question — and then takes the embedding of that text for retrieval.
📌 A simple example
User query:
“What were the key arguments in the Federalist Papers about checks and balances?”
🔸 Standard RAG:
- Take the embedding of the question → search for similar documents → sometimes mismatches occur due to differences in style or phrasing between the query and the source texts.
🔸 HyDE:
Let GPT first produce a mock answer, such as:
“The Federalist Papers argued that checks and balances prevent any one branch of government from gaining excessive power…”
Then, take the embedding of that generated paragraph to search for documents in the vector database.
🎯 Result: The system retrieves passages that genuinely discuss “checks and balances” in the Federalist Papers — improving both recall and relevance.
⚙️ Quy trình HyDE chi tiết:
User query →
GPT generates hypothetical answer →
Embed the hypothetical answer →
Retrieve documents from vector DB →
GPT answers using retrieved context💡 Why HyDE works better
- The embedding represents semantic content closer to the answer domain than the question domain.
- It bridges the query–document style gap, especially for long-form or academic text.
- Particularly helpful when the query is vague or poorly phrased.
🧱 When to use HyDE?
- Complex or abstract user queries
- Queries with limited context or ambiguous wording
- Knowledge domains with specialized or formal language (e.g., legal, scientific)
🧪 RAG vs. HyDE: Quick comparison
| Feature | Standard RAG | HyDE RAG |
|---|---|---|
| Embedding source | User query | Hypothetical answer |
| Retrieval quality | Depends on phrasing | Usually higher |
| Speed | Faster | Slightly slower |
| Ideal for | Clear queries | Ambiguous queries |
🛠️ Simple HyDE implementation (pseudo-code)
# Step 1: Generate hypothetical document from user query
hypo_answer = llm.generate("Write a short paragraph answering: " + user_query)
# Step 2: Embed hypothetical answer
embedding = embed_model.embed(hypo_answer)
# Step 3: Search documents using embedding
docs = vector_store.similarity_search(embedding)
# Step 4: Feed docs + query back to LLM to generate final answer
response = llm.generate(context=docs, question=user_query)🛠️ Tools that support HyDE
- LangChain’s HyDERetriever
- LlamaIndex integration
- Custom implementations using OpenAI or Cohere embeddings
📌 Practical notes
- Not always superior — if the query is already clear, HyDE might just add latency.
- Keep the generation prompt simple, e.g. “Write a short paragraph that answers the following question:”
- Cache hypothetical answers whenever possible to save cost and time.
🔚 In short:
HyDE is a “generate-then-search” strategy that helps AI systems retrieve more relevant documents by first hypothesizing what the answer might look like.
It shines in complex, ambiguous, or exploratory information-seeking scenarios — when users themselves may not know exactly what they’re asking.
LLM Engineer Starter Pack — Coming Soon
Build with LLMs. Get early access.